Baseline Model
Data Input:
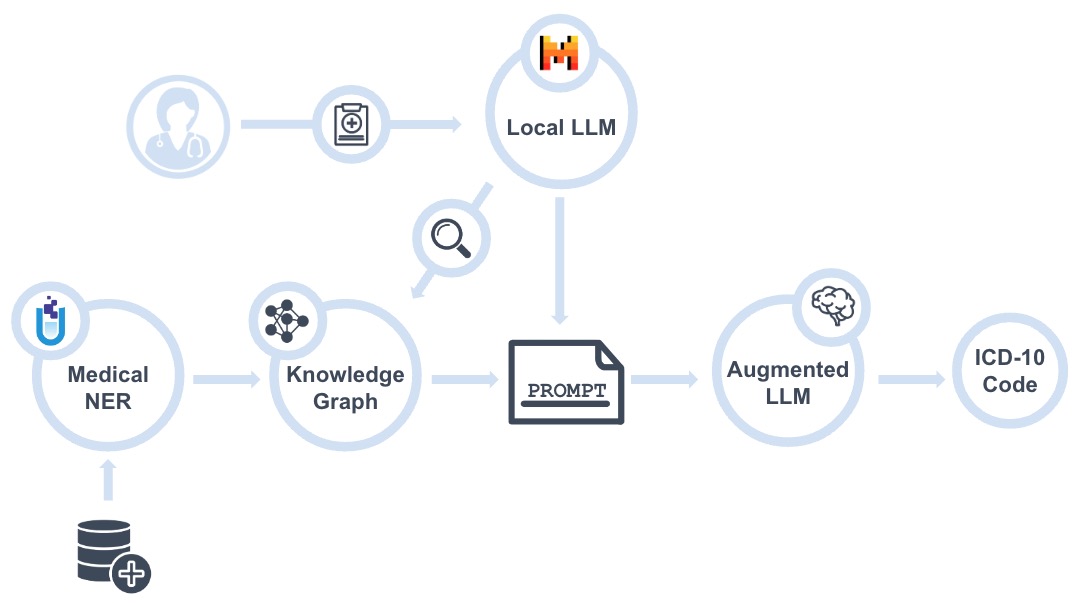
The process begins with a medical professional or healthcare provider who inputs clinical notes
into the system. The notes contain detailed information about a patient's symptoms, medical
history, and test results.
First Local LLM:
The clinical notes are first processed by a local LLM. This model is instructed and engineered
to extract the medical terminology and context within the notes, producing structured medical
entities in a sandardized output.
Second Local LLM Processing:
The structured medical entities generated by the first LLM are fed into the prompt for the
second local LLM that predicts ICD-10 Codes. The prompt includes additional context and
instructions to constrain the LLM's response to ensure that the output is relevant and in a
standardized format.
ICD-10 Code Prediction:
Finally, the second LLM predicts the most likely ICD-10 code based on the included medical
entities and the instructions provided via the prompt.
RAG Model
Retrieval:
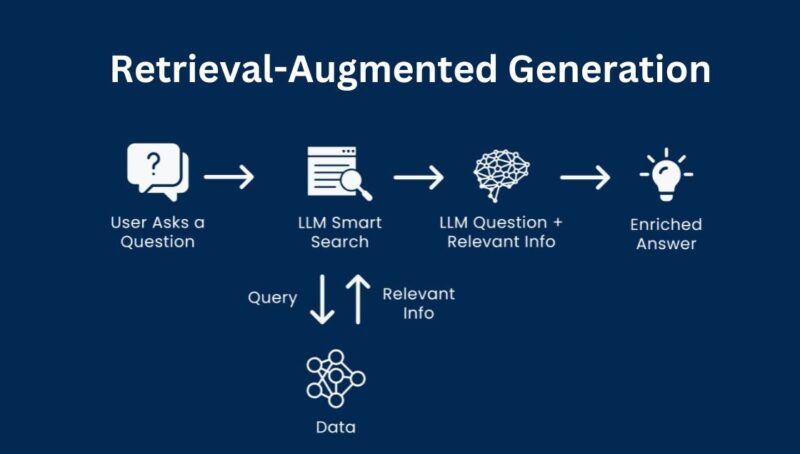
To augment the second LLM that performs ICD-10 code prediction, the system performs a retrieval
step, querying our previously constructed knowledge graph to find relevant information that can
provide additional context and support for assigning the correct ICD-10 code to the clinical
notes.
Query Augmentation:
The information retrieved in the previous step is used to augment the final prompt. This
augmented prompt now includes not only the instructions and the original details from the
clinical notes, but also supplementary information from the knowledge graph. This step ensures
that the model has access to a broader knowledge base and can consider additional,
contextually-relevant information when making predictions.